Code2Prompt を開発した理由
私は、Large Language Models (LLMs) がコーディングワークフローをどのように変革するか、テストやドキュメント文字列の生成、さらには数分で機能を出荷することに興味を持っています。しかし、これらのモデルをさらに押し進めるにつれて、いくつかの重要な課題が表面化しました。
| 計画の困難さ | 高いトークンコスト | 幻覚 |
|---|---|---|
| 🧠 ➡️ 🤯 | 🔥 ➡️ 💸 | 💬 ➡️ 🌀 |
そこで、私は code2prompt に貢献し始めました。これは、Rust ベースのツールで、LLM に適切なコンテキストを供給するのに役立ちます。
この投稿では、私の旅を共有し、なぜ code2prompt が今日の関連性があり、統合が簡単で、私の頼りになるソリューションになったのかを説明します。
LLM との最初のステップ 👣
Section titled “LLM との最初のステップ 👣”私は 2023 年 11 月に OpenAI Playground で text-davinci-003 を使って LLM を実験し始めました。言語モデルは新しい革命をもたらしました。優れた新しいアシスタントが、ほぼコマンドに従って単体テストやドキュメント文字列を生成するように感じました。私はモデルを限界まで押し上げ、小さな会話から倫理的なジレンマ、脱獄、そして複雑なコーディングタスクまで、すべてをテストしました。しかし、より大規模なプロジェクトに取り組むにつれて、モデルには明らかな限界があることにすぐに気付きました。最初は、コンテキストウィンドウに数百行のコードしか収められず、モデルはコードの目的や構造を理解するのに苦労することがよくありました。そのため、コンテキストの重要性が極めて高いことにすぐに気付きました。より簡潔な命令とより良いコンテキストが、結果をより良くするのです。
モデルの進化 🏗️
Section titled “モデルの進化 🏗️”モデルは印象的な結果を生み出しましたが、より大きなコードベースや複雑なタスクでは苦労することがよくありました。私は、プロンプトを作成することに多くの時間を費やすよりも、実際にコーディングすることに多くの時間を費やしていることに気付きました。同時に、モデルは新しいバージョンのリリースとともに改善を続け、推論能力とコンテキストサイズが向上し、新しい視点や可能性が広がりました。その後、コンテキストウィンドウにほぼ 2000 行のコードを収めることができ、結果が向上しました。数回の反復で機能全体を記述することができ、結果が得られる速度に驚かされました。私は、LLM がコーディングの未来であると確信し、その革命の一部になりたいと考えました。
LLM による最初のプロジェクト 🚀
Section titled “LLM による最初のプロジェクト 🚀”私は、ロボット競技用の ROS パスファインディングモジュールを作成し、クリーンアーキテクチャの Flutter クロスプラットフォームアプリの機能を生成し、Next.js で小さなウェブアプリを作成して経費を管理しました。私は、見慣れないフレームワークでこの小さなアプリを 1 日で構築できたことが、大きな転換点となりました。LLM は単なるツールではなく、乗数であることを実感しました。私は、bboxconverter というバウンディングボックスを変換するパッケージを開発し、他にも多くのプロジェクトを行いました。LLM は、新しいテクノロジーやフレームワークを迅速に学ぶのに役立ちます。
新しいパラダイム: Software 3.0 💡
Section titled “新しいパラダイム: Software 3.0 💡”私は、LLM をさらに深く掘り下げ、エージェントや足場を構築し始めました。私は、RestGPT という有名な論文を再現しました。アイデアは素晴らしいものでした。LLM に OpenAPI 仕様のある REST API を呼び出す能力を与えることです。Spotify や TMDB のような。これらの機能は、Software 3.0 と呼ぶ新しいソフトウェアプログラミングパラダイムを導入します。
| Software 1.0 | Software 2.0 | Software 3.0 |
|---|---|---|
| ルールベース | データ駆動型 | エージェント型 |
同じアイデアが MCP プロトコルを推進しました。このプロトコルにより、LLM はツールやリソースを直接呼び出すことができます。
LLM の限界 🧩
Section titled “LLM の限界 🧩”私は、RestGPT の有名な論文を再現しながら、LLM の深刻な限界に気付きました。論文の著者も私と同じ問題に遭遇しました。LLM は 幻覚 を起こしていました。実装されていないコードを生成し、引数をでっち上げ、単に命令に従うだけで、常識を働かせませんでした。
コンテキストサイズの制限 📏
Section titled “コンテキストサイズの制限 📏”もう 1 つの限界はコンテキストサイズでした。LLM は、針を見つけることは得意ですが、意味を理解するのは苦手です。言語モデルにコンテキストを多く与えすぎると、詳細に迷い込み、全体像を見失いがちになります。
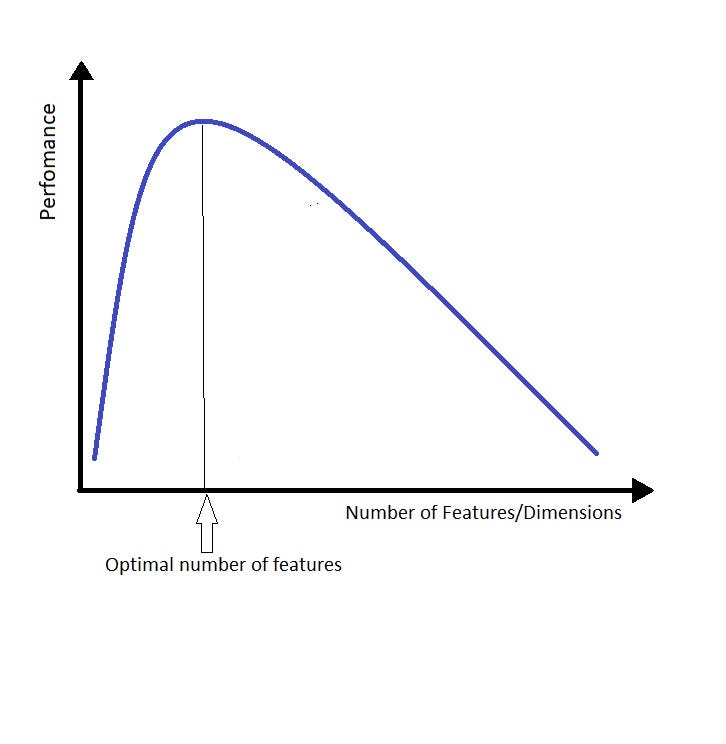
コンテキストを増やすと、LLM が正しい答えを見つけるのが難しくなります。私たちは、コンテキストサイズに関して妥協点を見つける必要があります。
より良い方法の探求: code2prompt 🔨
Section titled “より良い方法の探求: code2prompt 🔨”そこで、私はコードコンテキストを迅速にロード、フィルタリング、整理する方法を必要としました。ファイルを手動でコピーしたり、スニペットをプロンプトに貼り付けたりしていましたが、これは煩雑でエラーが発生しやすい作業でした。そこで、私はコンテキストを自動化するツールを探し始めました。そして、ある日、Google で “code2prompt” を検索したところ、Mufeed による Rust ベースのプロジェクト を見つけました。このプロジェクトは約 200 個のスターを獲得していました。当時は基本的な CLI ツールでしたが、フィルター機能やテンプレートは限られていました。私は大きな可能性を感じ、すぐにコントリビューターになりました。
ビジョンと統合 🔮
Section titled “ビジョンと統合 🔮”今日、LLM にコンテキストを提供する方法はたくさんあります。より大きなコンテキストから生成したり、Retrieval-Augmented Generation (RAG) を使用したり、コードを圧縮したり、これらの手法の組み合わせを使用したりできます。コンテキストの構築はホットトピックであり、今後数ヶ月で急速に進化するでしょう。しかし、私のアプローチは KISS です。Keep It Simple, Stupid です。LLM にコンテキストを提供する最も簡単で効率的な方法は、必要に応じてコンテキストを正確に構築することです。これは RAG とは異なり、決定論的です。
エージェントとの統合 👤
Section titled “エージェントとの統合 👤”私は、将来のエージェントはコンテキストを摂取する方法を必要とし、 code2prompt はそれを行う簡単で効率的な方法であると信じています。コードベースやドキュメント、メモなどのテキストリポジトリに最適です。 code2prompt を使用するのに最適な場所は、意味のある名前の規約があるコードベースです。たとえば、クリーンアーキテクチャでは、関心の分離とレイヤーが明確に分かれています。関連するコンテキストは通常、異なるファイルやフォルダーにありますが、同じ名前を共有します。
Glob パターン優先: ファイルを選択または除外するのが簡単です。
さらに、コアライブラリはステートフルコンテキストマネージャーとして設計されており、会話が進むにつれてファイルを追加または削除できます。これは、特定のタスクや目標のためのコンテキストを提供する場合に特に便利です。
ステートフルコンテキスト: 会話が進むにつれてファイルを追加または削除できます。
これらの機能により、 code2prompt はエージェントベースのワークフローの最適なツールになります。MCP サーバーを使用すると、Aider や Goose などの人気のある AI エージェントフレームワークとシームレスに統合できます。
Code2prompt が重要な理由 ✊
Section titled “Code2prompt が重要な理由 ✊”LLM が進化し、コンテキストウィンドウが拡大するにつれて、リポジトリ全体をプロンプトに強制的に押し込むだけで十分であるように思えるかもしれません。しかし、トークンコスト と プロンプトの一貫性 は依然として、小規模な企業や開発者にとって大きな障害です。重要なコードに焦点を当てることで、 code2prompt は LLM の使用を効率的でコスト効果が高く、幻覚を起こしにくくします。
要するに:
- 幻覚を減らす ことで、適切な量のコンテキストを提供します。
- トークン使用コストを減らす ことで、適切なコンテキストを手動でキュレートします。
- LLM のパフォーマンスを向上させる ことで、適切な量のコンテキストを提供します。
- テキストリポジトリ用のコンテキストフィーダーとして、エージェントスタックと統合します。
オープンソースです! 🌐
Section titled “オープンソースです! 🌐”新しいコントリビューターは大歓迎です! Rust や革新的な AI ツールの構築に興味がある場合、またはコードベースのプロンプト用のより優れたワークフローを探している場合は、ぜひ参加してください。
このブログ投稿を最後まで読んでいただき、私のストーリーが code2prompt をチェックするきっかけになれば幸いです。
Olivier D’Ancona
このページは便宜上、自動的に翻訳されています。元のコンテンツについては英語版を参照してください。