Pourquoi j'ai développé Code2Prompt
Introduction
Section intitulée « Introduction »Je suis toujours fasciné par la façon dont les modèles de langage à grande échelle (LLM) transforment les flux de travail de codage - générant des tests, des docstrings ou même des fonctionnalités entières en quelques minutes. Mais à mesure que je poussais ces modèles plus loin, quelques points de douleur critiques continuaient à émerger :
| Difficultés de planification | Coûts de jetons élevés | Hallucinations |
|---|---|---|
| 🧠 ➡️ 🤯 | 🔥 ➡️ 💸 | 💬 ➡️ 🌀 |
C’est pourquoi j’ai commencé à contribuer à code2prompt, un outil basé sur Rust pour aider à fournir juste le contexte approprié aux LLM.
Dans cet article, je partagerai mon parcours et expliquerai pourquoi je suis convaincu que code2prompt est pertinent aujourd’hui et s’intègre si bien, et pourquoi il est devenu ma solution incontournable pour des flux de travail de codage IA meilleurs et plus rapides.
Mes premiers pas avec les LLM 👣
Section intitulée « Mes premiers pas avec les LLM 👣 »J’ai commencé à expérimenter avec les LLM sur OpenAI Playground avec text-davinci-003 lorsqu’il a gagné en popularité en novembre 2023. Les modèles de langage ont permis une nouvelle révolution. Cela ressemblait à avoir un assistant brillant qui pouvait produire des tests unitaires et des docstrings presque sur commande. J’ai apprécié pousser les modèles à leurs limites - testant tout, des conversations informelles et des dilemmes éthiques aux jailbreaks et aux tâches de codage complexes. Cependant, à mesure que j’ai abordé des projets plus importants, j’ai rapidement réalisé que les modèles avaient des limitations criantes. Au début, je ne pouvais adapter que quelques centaines de lignes de code dans la fenêtre de contexte, et même alors, les modèles avaient souvent du mal à comprendre le but ou la structure du code. C’est pourquoi j’ai rapidement remarqué que l’importance du contexte était primordiale. Plus mes instructions étaient concises et meilleur était le contexte, meilleurs étaient les résultats.
Évolution des modèles 🏗️
Section intitulée « Évolution des modèles 🏗️ »Les modèles pouvaient produire des résultats impressionnants mais avaient souvent du mal avec des bases de code plus importantes ou des tâches complexes. Je me suis retrouvé à passer plus de temps à élaborer des invites qu’à coder réellement. Dans le même temps, les modèles continuaient à s’améliorer avec la sortie de nouvelles versions. Ils ont augmenté leurs capacités de raisonnement et la taille du contexte, offrant de nouvelles perspectives et possibilités. Je pouvais adapter presque deux mille lignes de code dans la fenêtre de contexte, et les résultats se sont améliorés. Je pouvais écrire des fonctionnalités entières en quelques itérations, et j’ai été impressionné par la rapidité avec laquelle je pouvais obtenir des résultats. J’étais convaincu que les LLM étaient l’avenir du codage, et je voulais en faire partie. Je crois fermement que l’IA ne nous remplacera pas encore. Mais nous assistera sous la forme d’assistants où les humains sont les experts encore en contrôle.
Mes premiers projets avec les LLM 🚀
Section intitulée « Mes premiers projets avec les LLM 🚀 »J’ai commencé à écrire un module de recherche de chemin ROS pour un concours de robotique, à générer des fonctionnalités pour une application Flutter multiplateforme d’architecture propre, et j’ai créé une petite application Web pour suivre mes dépenses en Next.js. Le fait que j’ai construit cette petite application en une soirée, dans un framework que je n’avais jamais utilisé auparavant, a été un moment décisif pour moi ; les LLM n’étaient pas seulement des outils mais des multiplicateurs. J’ai développé bboxconverter, un package pour convertir des boîtes de bounding, et la liste continue. Les LLM peuvent vous aider à apprendre de nouvelles technologies et frameworks rapidement ; c’est incroyable.
Un nouveau paradigme : Software 3.0 💡
Section intitulée « Un nouveau paradigme : Software 3.0 💡 »Je me suis approfondi dans les LLM et j’ai commencé à construire des agents et des squelettes autour d’eux. J’ai reproduit le célèbre article RestGPT. L’idée est excellente : donner aux LLM la capacité d’appeler certaines API REST avec une spécification OpenAPI, telles que Spotify ou TMDB. Ces capacités introduisent un nouveau paradigme de programmation logiciel, que j’aime appeler Software 3.0.
| Software 1.0 | Software 2.0 | Software 3.0 |
|---|---|---|
| Basé sur des règles | Piloté par les données | Agence |
La même idée a propulsé le protocole MCP, qui permet aux LLM d’appeler des outils et des ressources directement de manière transparente, car par conception, l’outil a besoin d’une description pour être appelé par le LLM, contrairement aux API REST qui ne nécessitent pas nécessairement de spécification OpenAPI.
Les limitations des LLM 🧩
Section intitulée « Les limitations des LLM 🧩 »Hallucinations 🌀
Section intitulée « Hallucinations 🌀 »Lors de la reproduction du célèbre article RESTGPT, j’ai remarqué certaines limitations graves des LLM. Les auteurs de l’article ont rencontré les mêmes problèmes que moi : les LLM hallucinaient. Ils génèrent du code qui n’est pas implémenté, inventant des arguments et suivant simplement les instructions à la lettre sans utiliser le bon sens. Par exemple, dans le code source original de RestGPT, les auteurs ont demandé dans l’invite de l’appelant.
“de ne pas être malin et d’inventer des étapes qui n’existent pas dans le plan.”
J’ai trouvé cette déclaration amusante et très intéressante parce que c’était la première fois que je rencontrais quelqu’un qui instruisait les LLM à ne pas halluciner.
Taille de contexte limitée 📏
Section intitulée « Taille de contexte limitée 📏 »Une autre limitation était la taille du contexte ; les LLM performent bien pour trouver l’aiguille dans la botte de foin mais ont du mal à en comprendre le sens. Lorsque vous donnez trop de contexte aux modèles de langage, ils ont tendance à se perdre dans les détails et à perdre de vue l’ensemble, ce qui est ennuyeux et nécessite une direction constante. La façon dont j’aime y penser est similaire à la malédiction de la dimensionnalité. Remplacez le mot “dimension” ou “fonctionnalité” par “contexte”, et vous obtenez l’idée.
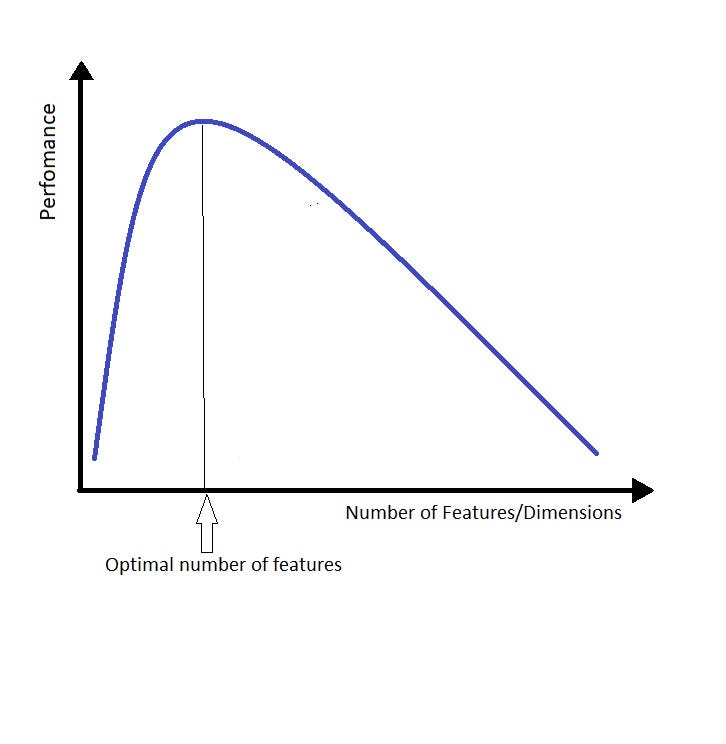
Plus vous donnez de contexte au LLM, plus il est difficile de trouver la bonne réponse. J’ai créé une phrase agréable pour résumer cette idée :
Fournissez aussi peu de contexte que possible mais autant que nécessaire
Ceci est fortement inspiré par la célèbre citation d’Alain Berset, un politicien suisse 🇨🇭 qui a déclaré pendant le confinement COVID-19 :
“Nous souhaitons agir aussi vite que possible, mais aussi lentement que nécessaire”
Cela représente l’idée de compromis et s’applique à la taille du contexte des LLM !
Recherche d’une meilleure façon : code2prompt 🔨
Section intitulée « Recherche d’une meilleure façon : code2prompt 🔨 »Par conséquent, j’avais besoin d’un moyen de charger, de filtrer et d’organiser rapidement mon contexte de code en fournissant la moindre quantité possible de contexte avec la meilleure qualité possible. J’ai essayé de copier manuellement des fichiers ou des extraits dans des invites, mais cela est devenu encombrant et sujet aux erreurs. Je savais que l’automatisation du processus fastidieux de forgeage du contexte pour poser de meilleures questions serait utile. Ensuite, un jour, j’ai tapé “code2prompt” sur Google, espérant trouver un outil qui acheminait mon code directement dans des invites.
Et voici ! J’ai découvert un projet basé sur Rust de Mufeed nommé code2prompt, qui comptait environ 200 étoiles sur GitHub. C’était encore basique à l’époque : un simple outil CLI avec une capacité de filtration limitée et des modèles. J’ai vu un énorme potentiel et j’ai sauté directement pour contribuer, en mettant en œuvre la correspondance de modèles globaux, entre autres fonctionnalités, et je suis rapidement devenu le principal contributeur.
Vision & Intégrations 🔮
Section intitulée « Vision & Intégrations 🔮 »Aujourd’hui, il existe plusieurs façons de fournir du contexte aux LLM. Générer à partir du contexte plus large, utiliser la génération augmentée de récupération (RAG), compresser le code, ou même utiliser une combinaison de ces méthodes. Le forgeage de contexte est un sujet brûlant qui évoluera rapidement dans les prochains mois. Cependant, mon approche est KISS : Keep It Simple, Stupid. La meilleure façon de fournir du contexte aux LLM est d’utiliser la façon la plus simple et la plus efficace possible. Vous forgez précisément le contexte dont vous avez besoin ; c’est déterministe, contrairement à RAG.
C’est pourquoi j’ai décidé de pousser code2prompt plus loin en tant qu’outil simple pouvant être utilisé dans n’importe quel flux de travail. Je voulais le rendre facile à utiliser, facile à intégrer et facile à étendre. C’est pourquoi j’ai ajouté de nouvelles façons d’interagir avec l’outil.
- Core : Le cœur de
code2promptest une bibliothèque Rust qui fournit la fonctionnalité de base pour forger le contexte à partir de votre base de code. Il comprend une API simple pour charger, filtrer et organiser votre contexte de code. - CLI : L’interface de ligne de commande est la façon la plus simple d’utiliser
code2prompt. Vous pouvez forger le contexte à partir de votre base de code et le canaliser directement dans vos invites. - API Python : L’API Python est un simple wrapper autour de CLI qui vous permet d’utiliser
code2promptdans vos scripts et agents Python. Vous pouvez forger le contexte à partir de votre base de code et le canaliser directement dans vos invites. - MCP : Le serveur MCP
code2promptpermet aux LLM d’utilisercode2prompten tant qu’outil, les rendant ainsi capables de forger le contexte.
La vision est décrite plus en détail dans la page de vision de la documentation.
Intégration avec les agents 👤
Section intitulée « Intégration avec les agents 👤 »Je crois que les futurs agents auront besoin d’un moyen d’ingérer du contexte, et code2prompt est la façon simple et efficace de le faire pour les référentiels textuels comme la base de code, la documentation ou les notes. Un endroit typique pour utiliser code2prompt serait dans une base de code avec des conventions de dénomination significatives. Par exemple, dans l’architecture propre, il existe une séparation claire des préoccupations et des couches. Le contexte pertinent réside généralement dans différents fichiers et dossiers mais partage le même nom. C’est un cas d’utilisation parfait pour code2prompt, où vous pouvez utiliser le modèle global pour saisir les fichiers pertinents.
Basé sur le modèle global : Sélectionnez ou excluez précisément les fichiers avec un minimum de tracas.
En outre, la bibliothèque principale est conçue en tant que gestionnaire de contexte étatique, vous permettant d’ajouter ou de supprimer des fichiers à mesure que votre conversation avec le LLM évolue. Ceci est particulièrement utile pour fournir du contexte pour une tâche ou un objectif spécifique. Vous pouvez facilement ajouter ou supprimer des fichiers du contexte sans relancer le processus.
Contexte étatique : Ajoutez ou supprimez des fichiers à mesure que votre conversation avec le LLM évolue.
Ces capacités font de code2prompt un choix parfait pour les flux de travail basés sur des agents. Le serveur MCP permet une intégration transparente avec des frameworks d’agents IA populaires tels que Aider, Goose, ou Cline. Laissez-les gérer des objectifs complexes pendant que code2prompt fournit le contexte de code parfait.
Pourquoi Code2prompt compte ✊
Section intitulée « Pourquoi Code2prompt compte ✊ »À mesure que les LLM évoluent et que les fenêtres de contexte s’étendent, il peut sembler que simplement forcer des référentiels entiers dans des invites suffit. Cependant, les coûts de jetons et la cohérence des invites restent des obstacles importants pour les petites entreprises et les développeurs. En se concentrant sur le code qui compte, code2prompt maintient votre utilisation de LLM efficace, rentable et moins encline à l’hallucination.
En bref :
- Réduire les hallucinations en fournissant la bonne quantité de contexte
- Réduire les coûts de jetons en curant manuellement le contexte approprié nécessaire
- Améliorer les performances de LLM en donnant la bonne quantité de contexte
- Intègre la pile agence en tant que fournisseur de contexte pour les référentiels textuels
Vous pouvez rejoindre ! C’est Open Source ! 🌐
Section intitulée « Vous pouvez rejoindre ! C’est Open Source ! 🌐 »Tout nouveau contributeur est le bienvenu ! Venez à bord si vous êtes intéressé par Rust, la création d’outils IA innovants, ou si vous voulez simplement un meilleur flux de travail pour vos invites basées sur le code.
Merci de lire, et j’espère que mon histoire vous a inspiré à découvrir code2prompt. C’est un incroyable voyage, et cela ne fait que commencer !
Olivier D’Ancona
Cette page a été traduite automatiquement pour votre commodité. Veuillez vous référer à la version anglaise pour le contenu original.