Por qué desarrollé Code2Prompt
Introducción
Sección titulada «Introducción»Siempre me ha fascinado cómo los modelos de lenguaje grandes (LLM) transforman los flujos de trabajo de codificación, generando pruebas, docstrings o incluso enviando características completas en minutos. Pero a medida que empujaba a estos modelos más lejos, surgían algunos puntos críticos:
| Dificultades de planificación | Altos costos de tokens | Alucinaciones |
|---|---|---|
| 🧠 ➡️ 🤯 | 🔥 ➡️ 💸 | 💬 ➡️ 🌀 |
Es por eso que comencé a contribuir a code2prompt, una herramienta basada en Rust para ayudar a proporcionar el contexto adecuado a los LLM.
En este post, compartiré mi viaje y explicaré por qué estoy convencido de que code2prompt es relevante hoy en día y se integra tan bien, y por qué se ha convertido en mi solución para flujos de trabajo de codificación con inteligencia artificial más rápidos y mejores.
Mis primeros pasos con LLM 👣
Sección titulada «Mis primeros pasos con LLM 👣»Comencé a experimentar con LLM en OpenAI Playground con text-davinci-003 cuando ganó popularidad en noviembre de 2023. Los modelos de lenguaje permitieron una nueva revolución. Se sintió como tener un asistente brillante que generaba pruebas unitarias y docstrings casi a pedido. Disfruté empujando a los modelos a sus límites, probando todo, desde charlas pequeñas y dilemas éticos hasta jailbreaks y tareas de codificación complejas. Sin embargo, a medida que asumí proyectos más extensos, rápidamente me di cuenta de que los modelos tenían limitaciones evidentes. Al principio, solo podía ajustar unas pocas cientos de líneas de código en la ventana de contexto, y ni siquiera entonces, los modelos a menudo luchaban por comprender el propósito o la estructura del código. Es por eso que rápidamente noté que la importancia del contexto era fundamental. Cuanto más concisas eran mis instrucciones y mejor era el contexto, mejores eran los resultados.
Evolución del modelo 🏗️
Sección titulada «Evolución del modelo 🏗️»Los modelos podían producir resultados impresionantes, pero a menudo luchaban con bases de código más grandes o tareas complejas. Me encontré pasando más tiempo elaborando indicaciones que codificando. Al mismo tiempo, los modelos seguían mejorando con el lanzamiento de nuevas versiones. Aumentaron las habilidades de razonamiento y el tamaño del contexto, ofreciendo nuevas perspectivas y posibilidades. Pude ajustar casi dos mil líneas de código en la ventana de contexto, y los resultados mejoraron. Pude escribir características completas en cuestión de unas pocas iteraciones, y me asombré de lo rápido que podía obtener resultados. Estaba convencido de que los LLM eran el futuro de la codificación, y quería ser parte de esa revolución. Creo firmemente que la inteligencia artificial no nos reemplazará todavía. Pero nos asistirá en forma de asistentes donde los humanos siguen siendo los expertos en control.
Mis primeros proyectos con LLM 🚀
Sección titulada «Mis primeros proyectos con LLM 🚀»Comencé a escribir un módulo de búsqueda de rutas ROS para una competencia robótica, generar características para una aplicación multiplataforma Flutter de arquitectura limpia, y creé una pequeña aplicación web para rastrear mis gastos en Next.js. El hecho de que construyera esta pequeña aplicación en una noche, en un marco que nunca había tocado antes, fue un momento que cambió el juego para mí; los LLM no eran solo herramientas, sino multiplicadores. Desarrollé bboxconverter, un paquete para convertir cajas de límites, y la lista sigue. Los LLM pueden ayudarlo a aprender nuevas tecnologías y marcos rápidamente; eso es genial.
Un nuevo paradigma: Software 3.0 💡
Sección titulada «Un nuevo paradigma: Software 3.0 💡»Me sumergí más en los LLM y comencé a construir agentes y andamiaje alrededor de ellos. Reproduje el famoso artículo RestGPT. La idea es excelente: dar a los LLM la capacidad de llamar a algunas API REST con una especificación OpenAPI, como Spotify o TMDB. Estas capacidades introducen un nuevo paradigma de programación de software, que me gusta llamar Software 3.0.
| Software 1.0 | Software 2.0 | Software 3.0 |
|---|---|---|
| Basado en reglas | Impulsado por datos | Agente |
La misma idea impulsó el protocolo MCP, que permite a los LLM llamar a herramientas y recursos directamente de manera fluida porque, por diseño, la herramienta necesita una descripción para ser llamada por el LLM en el opuesto de las API REST que no requieren necesariamente una especificación OpenAPI.
Las limitaciones de los LLM 🧩
Sección titulada «Las limitaciones de los LLM 🧩»Alucinaciones 🌀
Sección titulada «Alucinaciones 🌀»Mientras reproducía el famoso artículo RESTGPT, noté algunas limitaciones graves de los LLM. Los autores del artículo encontraron los mismos problemas que yo: los LLM estaban alucinando. Generan código que no se implementa, inventando argumentos y simplemente siguiendo las instrucciones al pie de la letra sin aprovechar el sentido común. Por ejemplo, en el código base original de RestGPT, los autores preguntaron en la indicación del llamador.
“para no ser astuto y hacer pasos que no existen en el plan”.
Encontré esta afirmación divertida y muy interesante porque fue la primera vez que encontré a alguien instruyendo a los LLM para que no alucinaran.
Tamaño de contexto limitado 📏
Sección titulada «Tamaño de contexto limitado 📏»Otra limitación fue el tamaño del contexto; los LLM se desempeñan bien para encontrar la aguja en el pajar, pero luchan por entenderlo. Cuando le das demasiado contexto a los modelos de lenguaje, tienden a perderse en los detalles y perder de vista la imagen general, lo cual es molesto y requiere una dirección constante. La forma en que me gusta pensar al respecto es de manera similar a la maldición de la dimensionalidad. Reemplaza la palabra “dimensión” o “característica” por “contexto”, y obtienes la idea.
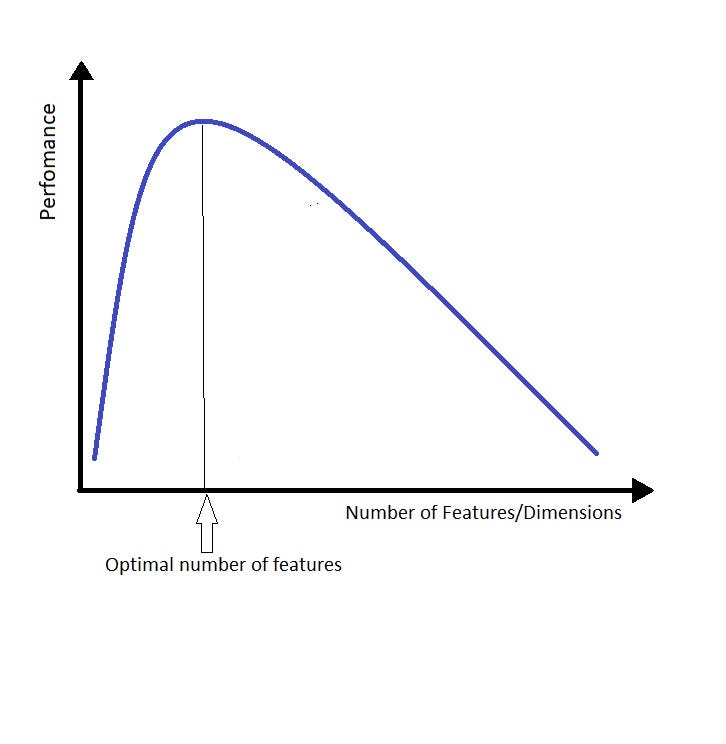
Cuanto más contexto le das al LLM, más difícil es encontrar la respuesta correcta. Surgí con una frase agradable para resumir esta idea:
Proporcionar la menor cantidad de contexto posible pero la necesaria
Esto está fuertemente inspirado en la famosa cita de Alain Berset, un político suizo 🇨🇭 que dijo durante el bloqueo de COVID-19:
“Queremos actuar lo más rápido posible, pero también lo más lentamente necesario”.
Esto representa la idea de compromiso y se aplica al tamaño del contexto de los LLM.
Buscando una mejor manera: code2prompt 🔨
Sección titulada «Buscando una mejor manera: code2prompt 🔨»Por lo tanto, necesitaba una forma de cargar, filtrar y organizar mi contexto de código rápidamente proporcionando la menor cantidad posible de contexto con la mejor calidad posible. Intenté copiar manualmente archivos o fragmentos en indicaciones, pero eso se volvió engorroso y propenso a errores. Sabía que automatizar el proceso tedioso de forjar el contexto para hacer mejores indicaciones sería útil. Luego, un día, escribí “code2prompt” en Google, esperando encontrar una herramienta que canalizara mi código directamente en indicaciones.
Y he aquí, descubrí un proyecto basado en Rust de Mufeed llamado code2prompt, con alrededor de 200 estrellas en GitHub. Todavía era básico en ese momento: una herramienta CLI simple con capacidad de filtro limitada y plantillas. Vi un enorme potencial y me uní directamente para contribuir, implementando la coincidencia de patrones glob, entre otras características, y pronto me convertí en el principal contribuyente.
Visión e integraciones 🔮
Sección titulada «Visión e integraciones 🔮»Hoy en día, hay varias formas de proporcionar contexto a los LLM. Generar a partir del contexto más grande, utilizando la generación aumentada de recuperación (RAG), comprimiendo el código, o incluso utilizando una combinación de estos métodos. La creación de contexto es un tema candente que evolucionará rápidamente en los próximos meses. Sin embargo, mi enfoque es KISS: Manténlo simple, estúpido. La mejor forma de proporcionar contexto a los LLM es utilizar la forma más simple y eficiente posible. Forjas precisamente el contexto que necesitas; es determinista, a diferencia de RAG.
Es por eso que decidí impulsar code2prompt más lejos como una herramienta simple que se puede utilizar en cualquier flujo de trabajo. Quería hacerlo fácil de usar, fácil de integrar y fácil de extender. Es por eso que agregué nuevas formas de interactuar con la herramienta.
- Núcleo: El núcleo de
code2promptes una biblioteca de Rust que proporciona la funcionalidad básica para forjar contexto a partir de tu base de código. Incluye una API simple para cargar, filtrar y organizar tu contexto de código. - CLI: La interfaz de línea de comandos es la forma más simple de usar
code2prompt. Puedes forjar contexto a partir de tu base de código y canalizarlo directamente en tus indicaciones. - API de Python: La API de Python es un envoltorio simple alrededor de la CLI que te permite usar
code2prompten tus scripts y agentes de Python. Puedes forjar contexto a partir de tu base de código y canalizarlo directamente en tus indicaciones. - MCP: El servidor MCP de
code2promptpermite a los LLM usarcode2promptcomo una herramienta, lo que les permite ser capaces de forjar el contexto.
La visión se describe más a fondo en la página de visión en el documento.
Integración con agentes 👤
Sección titulada «Integración con agentes 👤»Creo que los agentes futuros necesitarán tener una forma de ingerir contexto, y code2prompt es la forma simple y eficiente de hacerlo para repositorios textuales como bases de código, documentación o notas. Un lugar propicio para usar code2prompt sería en una base de código con convenciones de nombres significativas. Por ejemplo, en la arquitectura limpia, hay una clara separación de preocupaciones y capas. El contexto relevante suele residir en diferentes archivos y carpetas pero comparte el mismo nombre. Este es un caso de uso perfecto para code2prompt, donde puedes usar el patrón glob para agarrar los archivos relevantes.
Basado en patrones glob: Selecciona o excluye archivos con minimal molestia.
Además, la biblioteca central está diseñada como un administrador de contexto estatal, lo que te permite agregar o eliminar archivos a medida que evoluciona tu conversación con el LLM. Esto es particularmente útil cuando proporcionas contexto para una tarea o objetivo específico. Puedes agregar o eliminar archivos del contexto sin volver a ejecutar el proceso.
Contexto estatal: Agrega o elimina archivos a medida que evoluciona tu conversación con el LLM.
Estas capacidades hacen que code2prompt sea un ajuste perfecto para flujos de trabajo basados en agentes. El servidor MCP permite una integración perfecta con marcos de agentes de inteligencia artificial populares como Aider, Goose, o Cline. Dejan que manejen objetivos complejos mientras code2prompt entrega el contexto de código perfecto.
Por qué Code2prompt importa ✊
Sección titulada «Por qué Code2prompt importa ✊»A medida que los LLM evolucionan y las ventanas de contexto se expanden, puede parecer que simplemente forzar a los repositorios enteros en indicaciones es suficiente. Sin embargo, los costos de tokens y la coherencia de las indicaciones siguen siendo importantes obstáculos para las pequeñas empresas y los desarrolladores. Centrándose solo en el código que importa, code2prompt mantiene tu uso de LLM eficiente, rentable y menos propenso a la alucinación.
En resumen:
- Reduce las alucinaciones proporcionando la cantidad adecuada de contexto
- Reduce los costos de tokens mediante la curación manual del contexto adecuado necesario
- Mejora el rendimiento de LLM proporcionando la cantidad adecuada de contexto
- Integra la pila agéntica como un alimentador de contexto para repositorios textuales
Puedes unirte ¡Es de código abierto! 🌐
Sección titulada «Puedes unirte ¡Es de código abierto! 🌐»¡Todos los nuevos contribuyentes son bienvenidos! ¡Ven a bordo si estás interesado en Rust, forjando herramientas innovadoras de inteligencia artificial o simplemente quieres un mejor flujo de trabajo para tus indicaciones basadas en código!
Gracias por leer, y espero que mi historia te haya inspirado a revisar code2prompt. Ha sido un viaje increíble, y apenas está empezando.
Olivier D’Ancona
Esta página ha sido traducida automáticamente para su conveniencia. Consulte la versión en inglés para ver el contenido original.