Why I Developed Code2Prompt
Introduction
Section titled “Introduction”I’ve always been fascinated by how Large Language Models (LLMs) transform coding workflows—generating tests, docstrings, or even shipping entire features in minutes. But as I pushed these models further, a few critical pain points kept surfacing:
| Planning Difficulties | High Token Costs | Hallucinations |
|---|---|---|
| 🧠 ➡️ 🤯 | 🔥 ➡️ 💸 | 💬 ➡️ 🌀 |
That’s why I started contributing to code2prompt, a Rust-based tool to help feed just the proper context into LLMs.
In this post, I’ll share my journey and explain why I’m convinced that code2prompt is relevant today and integrates so well and why it’s become my go-to solution for better, faster AI coding workflows.
My First Steps with LLMs 👣
Section titled “My First Steps with LLMs 👣”I started experimenting with LLMs on OpenAI Playground with text-davinci-003 when it gained traction in November 2023. Language models enabled a new revolution. It felt like having a brilliant new assistant who would crank out unit tests and docstrings almost on command. I enjoyed pushing the models to their limits—testing everything from small talk and ethical dilemmas to jailbreaks and complex coding tasks. However, as I took on more extensive projects, I quickly realized that the models had glaring limitations. At first, I could only fit a few hundred lines of code into the context window, and even then, the models often struggled to understand the code’s purpose or structure. That’s why I quickly noticed that the importance of context was paramount. The more concise my instructions were and the better the context, the better the results.
Model Evolution 🏗️
Section titled “Model Evolution 🏗️”The models could produce impressive results but often struggled with larger codebases or complex tasks. I found myself spending more time crafting prompts than actually coding. At the same time, the models kept improving with the release of new versions. They increased reasoning abilities and context size, offering new perspectives and possibilities. I could fit almost two thousand lines of code into the context window then, and the results improved. I could write entire features in a matter of a few iterations, and I was amazed by how quickly I could get results. I was convinced that LLMs were the future of coding, and I wanted to be part of that revolution. I firmly believe that AI won’t replace us yet. But will assist us in the form of assistants where humans are the experts still in control.
My First Projects with LLMs🚀
Section titled “My First Projects with LLMs🚀”I started to write a ROS pathfinding module for a robotic competition, generate features for a clean architecture Flutter cross-platform app, and made a small web app to keep track of my expenses in Next.js. The fact that I built this small app in one evening, in a framework I’d never touched before, was a game-changer moment for me; LLMs weren’t just tools but multipliers. I developed `bboxconverter’, a package to convert bounding boxes, and the list goes on. LLMs can help you learn new technologies and frameworks quickly; that’s awesome.
A New Paradigm: Software 3.0 💡
Section titled “A New Paradigm: Software 3.0 💡”I dove deeper into LLMs and started to build agents and scaffold around them. I reproduced the famous paper RestGPT. The idea is excellent: give LLMs the ability to call some REST API with an OpenAPI specification, such as Spotify or TMDB. These capabilities introduce a new software programming paradigm, which I like to call Software 3.0.
| Software 1.0 | Software 2.0 | Software 3.0 |
|---|---|---|
| Rules-based | Data-driven | Agentic |
The same idea propelled the MCP protocol, which allows LLMs to call tools and resources directly in a seamless way because, by design, the tool needs a description to be called by the LLM in the opposite of REST Apis that doesn’t necessarily require OpenAPI specification.
The Limitations of LLMs 🧩
Section titled “The Limitations of LLMs 🧩”Hallucinations 🌀
Section titled “Hallucinations 🌀”While reproducing the famous paper RESTGPT, I noticed some serious limitations of LLMs. The paper’s authors encountered the same issues I had: LLMs were hallucinating. They generate code that is not implemented, inventing arguments and simply following the instructions to the letter without leveraging common sense. E.g., in the original RestGPT codebase, the authors asked in the caller prompt.
“to not get clever and make up steps that don’t exist in the plan.”
I found this statement funny and very interesting because it was the first time I encountered someone instructing LLMs not to hallucinate.
Limited Context-Size 📏
Section titled “Limited Context-Size 📏”Another limitation was the context size; LLMs perform well in finding the needle in the haystack but struggle to make sense of it. When you give too much context to the language models, they tend to get lost in the details and lose sight of the big picture, which is annoying and requires constant steering. The way I like to think about it is in a similar way as the curse of dimensionality. Replace the word “dimension” or “feature” by “context”, and you get the idea.
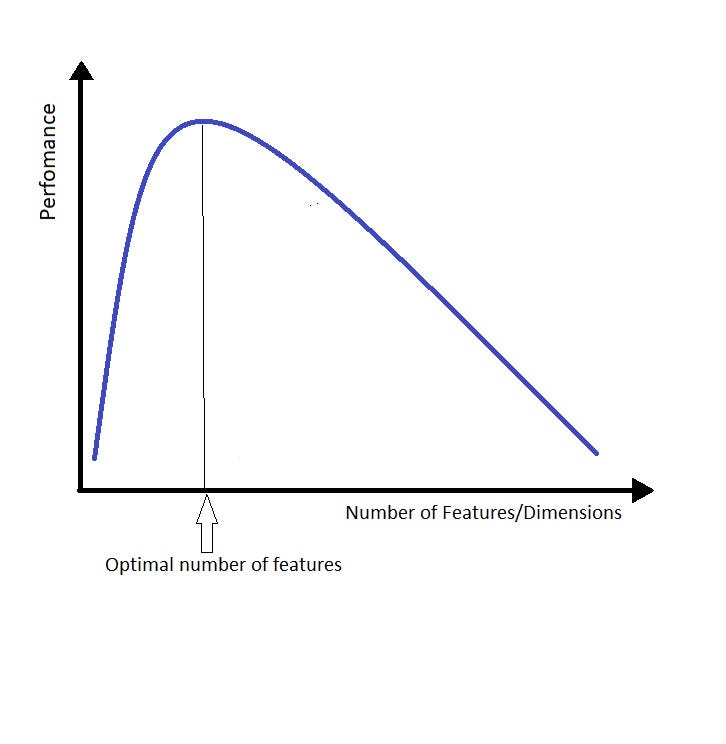
The more context you give to the LLM, the more difficult it is to find the correct answer. I came up with a nice sentence to summarize this idea:
Provide as little context as possible but as much as necessary
This is heavily inspired by the famous quote of Alain Berset, a Swiss politician 🇨🇭 who said during the COVID-19 lockdown:
“Nous souhaitons agir aussi vite que possible, mais aussi lentement que nécessaire”
This represents the idea of compromise and applies to the context size of LLMs!
Searching for a Better Way: code2prompt 🔨
Section titled “Searching for a Better Way: code2prompt 🔨”Therefore, I needed a way to load, filter, and organize my code context quickly by provisioning the least amount possible of context with the best quality possible. I tried manually copying files or snippets into prompts, but that became unwieldy and error-prone. I knew automating the tedious process of forging the context to ask better prompts would be helpful. Then, one day, I typed “code2prompt” into Google, hoping to find a tool that piped my code directly into prompts.
Lo and behold, I discovered a Rust-based project by Mufeed named code2prompt, sporting about 200 stars on GitHub. It was still basic at the time: a simple CLI tool with basic limited filter capacity and templates. I saw enormous potential and jumped in straight to contribute, implementing glob pattern matching, among other features, and soon became the main contributor.
Vision & Integrations 🔮
Section titled “Vision & Integrations 🔮”Today, there are several ways to provide context to LLMs. Generating from the larger context, using Retrieval-Augmented Generation (RAG), compressing the code, or even using a combination of these methods. Context forging is a hot topic that will evolve rapidly in the coming months. However, my approach is KISS: Keep It Simple, Stupid. The best way to provide context to LLMs is to use the simplest and most efficient way possible. You forge precisely the context you need; it’s deterministic, contrary to RAG.
That’s why I decided to push code2prompt further as a simple tool that can be used in any workflow. I wanted to make it easy to use, easy to integrate, and easy to extend. That’s why I added new ways to interact with the tool.
- Core: The core of
code2promptis a Rust library that provides the basic functionality to forge context from your codebase. It includes a simple API to load, filter, and organize your code context. - CLI: The command line interface is the simplest way to use
code2prompt. You can forge context from your codebase and pipe it directly into your prompts. - Python API: The Python API is a simple wrapper around the CLI that allows you to use
code2promptin your Python scripts and agents. You can forge context from your codebase and pipe it directly into your prompts. - MCP: The
code2promptMCP server allows LLMs to usecode2promptas a tool, thus making themselves capable of forging the context.
The vision is described further in the vision page in the doc.
Integration with agents 👤
Section titled “Integration with agents 👤”I believe that future agents will need to have a way to ingest context, and code2prompt is the simple and efficient way to do it for textual repositories like codebase, documentation, or notes. A propical place to use code2prompt would be in a codebase with meaningful naming conventions. For example, in clean architecture, there is a clear separation of concerns and layers. The relevant context usually resides in different files and folders but share the same name. This is a perfect use case for code2prompt, where you can use the glob pattern to grab the relevant files.
Glob Pattern-first: Precisely select or exclude files with minimal fuss.
Furthermore, the core library is designed as a stateful context manager, allowing you to add or remove files as your conversation with the LLM evolves. This is particularly useful when providing context for a specific task or goal. You can easily add or remove files from the context without re-running the process.
Stateful Context: Add or remove files as your conversation with the LLM evolves.
Those capabilities make code2prompt a perfect fit for agent-based workflows. The MCP server allows seamless integration with popular AI agent frameworks like Aider, Goose, or Cline. Let them handle complex goals while code2prompt delivers the perfect code context.
Why Code2prompt Matters ✊
Section titled “Why Code2prompt Matters ✊”As LLMs evolve and context windows expand, it might seem like purely brute-forcing entire repositories into prompts is enough. However, token costs and prompt coherence remain significant roadblocks for small companies and developers. Focusing on just the code that matters, code2prompt keeps your LLM usage efficient, cost-effective, and less prone to hallucination.
In short:
- Reduce hallucinations by providing the right amount of context
- Reduce token-usage costs by manually curating the proper context needed
- Improve LLM performance by giving the right amount of context
- Integrates the agentic stack as a context feeder for text repositories
You can join It’s Open Source! 🌐
Section titled “You can join It’s Open Source! 🌐”Every new contributor is welcome! Come aboard if you’re interested in Rust, forging innovative AI tools, or simply want a better workflow for your code-based prompts.
Thanks for reading, and I hope my story inspired you to check out code2prompt. It’s been an incredible journey, and it’s just getting started!
Olivier D’Ancona